


Near Real-Time Finance Data Warehousing Ussing Apache Spark and Delta Lake


Financial institutions globally deal with massive data volumes that calls for large scale data warehousing and effective processing of real-time transactions. In this blog, we shall discuss the current challenges in these areas and also understand how Delta lakes go a long way in overcoming some common hurdles
Problem Statement
Let us begin with the exploration of a use case: A Real-time transaction monitoring service for an online financial firm that deals with products such as “Pay Later and Personal Loan”. This firm needs:
- An alert mechanism to flag off fraud transactions – If a customer finds a small loophole in the underwriting rules then he can exploit the system by taking multiple PLs and online purchases through the Pay Later option which is very difficult and sometimes impossible to recover.
- Speeding up of troubleshooting and research in case of system failure or slowdown
- Tracking and evaluation of responses to Marketing campaigns, instantaneously
To achieve the above they want to build a near-real-time (NRT) data lake:
- To store ~400TB – last 2 years of historical transaction data
- Handle ~10k transaction records every 5 minutes results of various campaigns.
Note:
A typical transaction goes through multiple steps,
Capturing the transaction details Encryption of the transaction information Routing to the payment processor Return of either an approval or a decline notice. And the data lake should have a single record for each transaction and it should be the latest state.
Solution Choices
Approach 1: Create a Data Pipeline using Apache Spark – Structured Streaming (with data deduped)
A three steps process can be:
- Read the transaction data from Kafka every 5 minutes as micro-batches and store them as small parquet files
spark.readStream
.format(“kafka”)
.option(“kafka.bootstrap.servers”, “…”)
.option(“subscribe”, “topic”)
.load()
.selectExpr(“cast(value as string) as json”)
.select(from_json(“json”, schema).as(“data”))
.writeStream
.format(“parquet”)
.option(“path”, “/parquetTable/”)
.trigger(“5 minutes”)
.option(“checkpointLocation”, “…”)
.start()
- Merge all the new files and the historical data to come up with the new dataset at a regular interval, may be once in every 3 hrs and the same can be consumed in the downstream through any of the querying systems like Presto, AWS Athena, Google BigQuery, etc.
// 1. Take a backup of existing txn data
spark.read
.parquet(“/txn_parquetTable”)
.write
.mode(“overwrite”)
.format(“parquet”)
.save(“/temp/txn_parquetTable”)
// 2. Merge the existing txn data with new txn data keeping only the latest txn records
val windowSpec = Window.partitionBy($“txn_id”).orderBy($“txn_timestamp”.desc)
spark.read
.parquet(“/temp/txn_parquetTable”, “/parquetTable/”)
.withColumn(“record_num”, row_number().over(windowSpec))
.filter($”record_num”.eq(lit(1)))
.drop($“record_num”)
.write
.mode(“overwrite”)
.format(“parquet”)
.save(“/txn_parquetTable”)
- Create a Presto or Athena table to make this data available for querying.
Architecture

Challenges
- Preparing the consolidated data every 3 hours becomes challenging when the dataset size increases dramatically.
- If we increase the batch execution interval from 3 hours to more, say 6 or 12 hours then this isn’t NRT data lake,
- Any bug in the system if identified by the opportunists, can be exploited and can’t be tracked by IT teams immediately. By the time they see this on the dashboard (after 6 or 12 hours), the business would have already lost a significant amount of money.
- It’s also not very useful for monitoring specific event based campaign, e.g. 5% cashback on food delivery, on the day of “World Cup – Semi-final match”.
Approach 2: Create a Data Pipeline using Apache Spark – Structured Streaming (with duplicate data)
A two-steps process can be
- Read the transaction data from Kafka every 5 minutes as micro-batches and store them as small parquet files without any data deduplication,
spark.readStream
.format(“kafka”)
.option(“kafka.bootstrap.servers”, “…”)
.option(“subscribe”, “topic”)
.load()
.selectExpr(“cast(value as string) as json”)
.select(from_json(“json”, schema).as(“data”))
.writeStream
.format(“parquet”)
.option(“path”, “/parquetTable/”)
.trigger(“5 minutes”)
.option(“checkpointLocation”, “…”)
.start()
- Create an AWS Athena table on top of it and query the data properly,
-- 1. Table creation query
CREATE EXTERNAL TABLE IF NOT EXISTS pay_later.txn_fact (
txn_id string,
amount double,
status int,
...
txn_ts timestamp
)
PARTITIONED BY (txn_date string)
STORED AS PARQUET
LOCATION 's3://comp/paylater/txn_data/'
tblproperties ("parquet.compression"="SNAPPY");
-- 2. Query the above data with a where clause always
select
….
from
(select *,
row_number() over (partition by txn_id order by txn_timestamp) as record_num
from
Pay_later.txn_fact
where
record_num = 1
) as txn_fact2;
Architecture
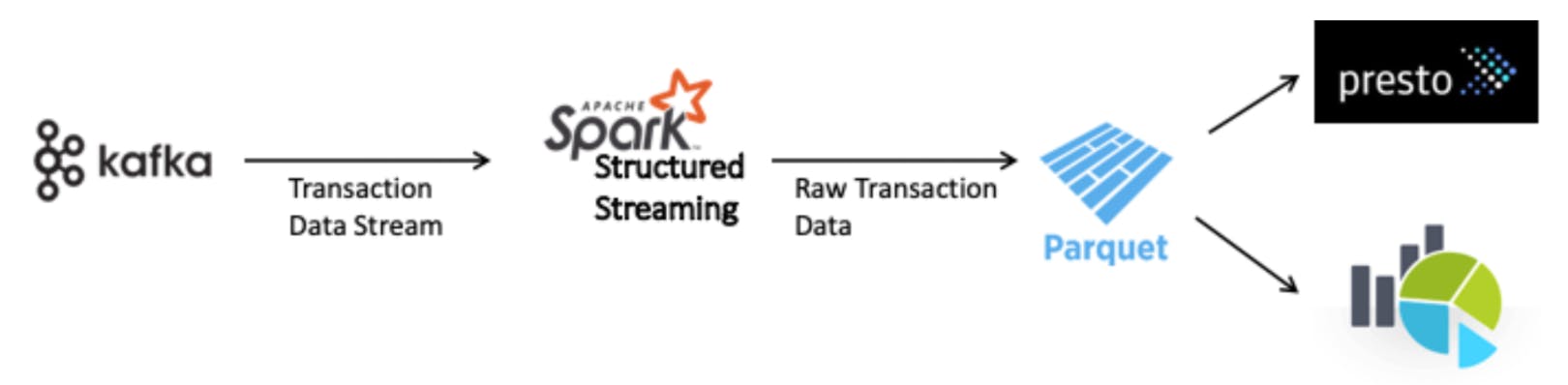
Challenges
Adding this additional “where” condition adds extra latency to each of the queries and it would soon become an extra overhead when the data reaches petabytes scale.
Summary
- In the 1st approach, there are 2 copies of the same data, one is the raw data and the other is the transaction data with the latest state. The raw copy of the data isn’t of any use and is also maintained in the Kafka topic.
- In the 2nd approach, we’re maintaining a single copy of the transaction base but it has duplicates. And we always have to add the filter condition of removing the stale transactions in our query.
Is there any way we can maintain only one copy of the transaction base with the latest transaction state and can provide an easy means to traverse through different snapshots?
Can we add the ACID properties to that single copy of the transaction base parquet table?
Delta Lake by Databricks addresses the above issues when used along with Apache Spark for not just Structured Streaming, but also for use with DataFrame (batch-based application).
A Quick Introduction to Delta Lake
Enterprises have been spending millions of dollars getting data into data lakes with Apache Spark. The aspiration is to do Machine Learning on all that data – Recommendation Engines, Forecasting, Fraud/Risk Detection, IoT & Predictive Maintenance, Genomics, DNA Sequencing and more. But majority of the projects fail to see fruition due to unreliable data and data that is not ready for ML.
~60% of big data projects are fail each year – Gartner.
These include data reliability challenges with data lakes, such as:
- Failed production jobs that leave data in a corrupt state requiring tedious recovery
- Lack of schema enforcement creating inconsistent and low quality data
- Lack of consistency making it almost impossible to mix appends and reads, batch and streaming
That’s where Delta Lake comes in. Some salient features are:
- Open format based on parquet
- Provides ACID transactions
- Apache Spark’s API
- Time Travel / Data Snapshots
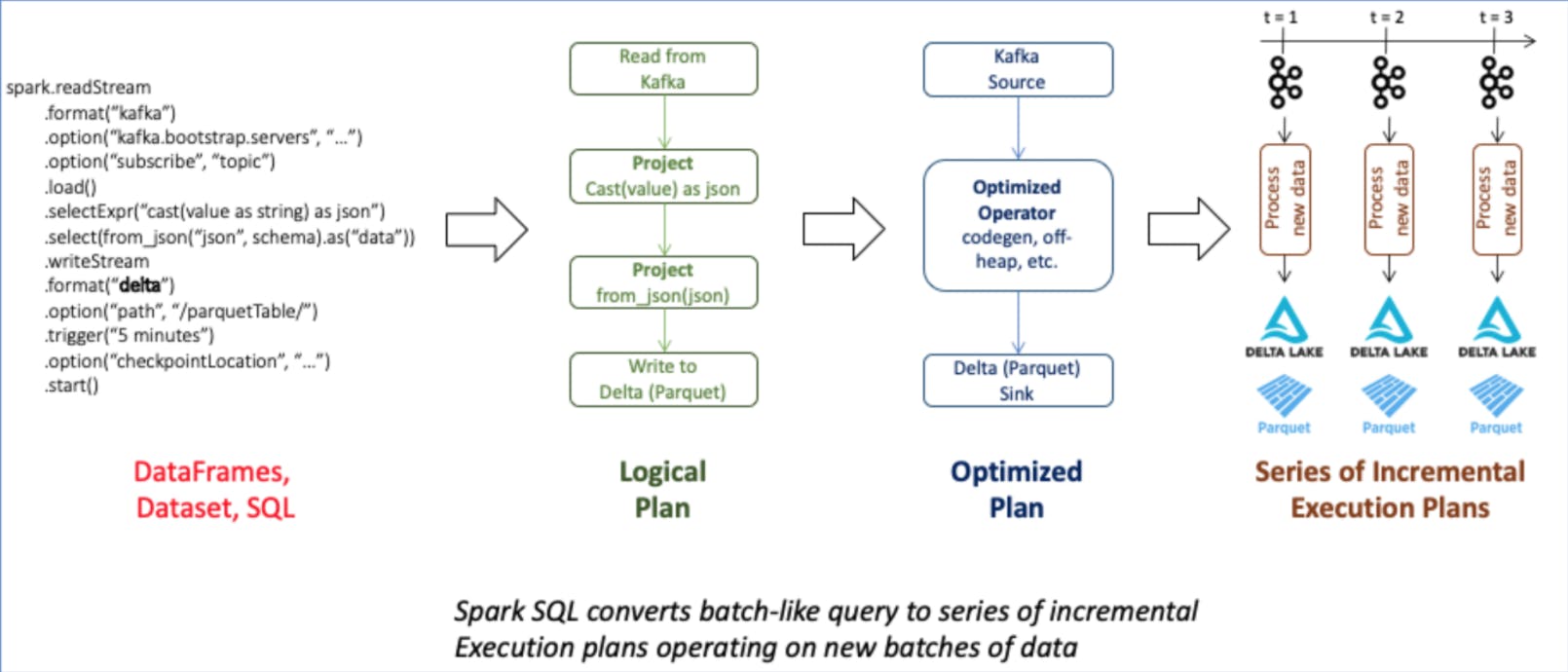
Project Architecture
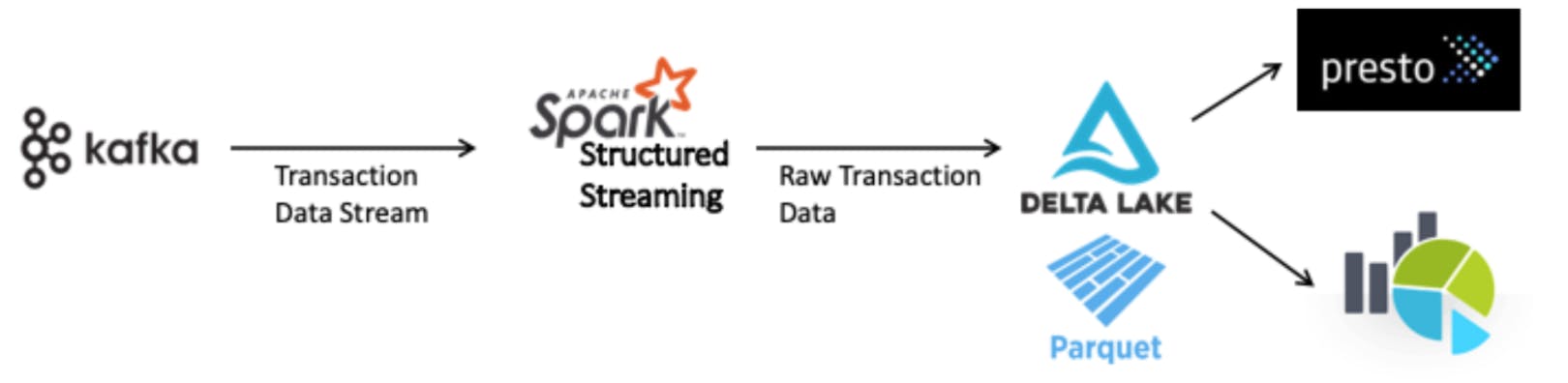
A three steps process for our use case
- Create a delta table by reading historical transaction data,
spark.sql(s"""
CREATE TABLE IF NOT EXISTS txn_all
USING DELTA
LOCATION "%s"
""".format(“s3n://comp/paylater/txn_data/”))
- Read the transaction data from Kafka every 5 minutes as micro-batches,
spark.readStream
.format(“kafka”)
.option(“kafka.bootstrap.servers”, “…”)
.option(“subscribe”, “topic”)
.load()
.selectExpr(“cast(value as string) as json”)
.select(from_json(“json”, schema).as(“data”))
.createOrReplacetempView(“txn_last_5mins”)
- Then merge them with the existing delta table
val mergeCmd = """
MERGE INTO txn_all
USING txn_last_5mins
ON txn_all.txn_id = txn_last_5mins.txn_id
WHEN MATCHED THEN
UPDATE SET
txn_all.status = txn_last_5mins.status
WHEN NOT MATCHED
THEN INSERT (txn_id, amount, status, ..., txn_ts)
VALUES (
txn_last_5mins.txn_id,
txn_last_5mins.amount,
txn_last_5mins.status,
...
txn_last_5mins.txn_ts)
"""
spark.sql(mergeCmd)
Conclusion
The table below indicates how solutions with Data Lakes & Delta lakes compare with each other on different parameters and highlights the advantages that Delta Lakes have to offer.

About the Author
Sidhartha Ray is Technical Lead at Sigmoid with expertise in Big Data – Apache Spark, Structured Streaming, Kafka, AWS Cloud and Service-less architecture. He is passionate about, designing and developing large scale cloud-based data pipelines and learning & evaluating new technologies.